Output
Installation Instructions
Usage
Configuration
Option documentation
Definition of terms
Report Formatting
Extracting Logs
Sample .rc file
Sample cron Script
Webtrax help
Updated 08 Nov 2023
Webtrax is a log file analysis program for NCSA web server logs. It works best on logs that include the "referrer" and "browser" info, such as the "NCSA Combined Format." Webtrax reads a web server's log file and produces up to twenty different graphical and tabular reports of hits, and the activities of individual site visitors, including what pages they viewed and for how long. Webtrax's output is extremely customizable.
The current version is version 23, updated 25 Mar 2006. updated
Webtrax is written in ![]() Perl and is therefore portable to many platforms. I have checked it on Macintosh, Windows 95, Linux, and FreeBSD Unix. The program is designed for small to medium size hit logs: it takes a few seconds on a 1GHz machine to analyze a 5000-hit log. I have analyzed logs ten times that big, but it takes a long time on a multi-user machine; Perl is interpreted, after all. Since Webtrax allocates all its working storage in memory, it's memory intensive, and might run out of gas on a small machine or choke on a log in the half-million-hit range. If I had 50,000 hits regularly, I'd look for a compiled program that used a real database.
Perl and is therefore portable to many platforms. I have checked it on Macintosh, Windows 95, Linux, and FreeBSD Unix. The program is designed for small to medium size hit logs: it takes a few seconds on a 1GHz machine to analyze a 5000-hit log. I have analyzed logs ten times that big, but it takes a long time on a multi-user machine; Perl is interpreted, after all. Since Webtrax allocates all its working storage in memory, it's memory intensive, and might run out of gas on a small machine or choke on a log in the half-million-hit range. If I had 50,000 hits regularly, I'd look for a compiled program that used a real database.
You're welcome to use webtrax however you like.
I have used it with automatically generated user log files that cover one day's worth of accesses, from various ISPs.
- Best Internet Services placed logs in the public_html directory early each morning.
- Pair Networks places a daily log extract in the directory www_logs, named www.yyyyMMdd, if you have a file called ".pair" in your home directory containing the word "AllExtended".
If you want to use this program with a log file that does not limit itself to one day's worth of accesses, you may wish to extract only the log records pertaining to a specific period (like yesterday, or last week), and run the program on them, rather than the entire log file. The program logextractor is supplied to do this.
Webtrax summarizes the logs it's given; some information may not get into the server logs because of
Information that isn't in the HTTP protocol. There is no unique identification of the person viewing the page included in the protocol. What we have is the IP address where the request came from. Assuming that this number corresponds to a single computer or a single "visitor" to the web site doesn't account for various IP sharing arrangements, proxies, multi-user computers, serial use of the same computer by many people, dialup pools, and many other possible confounding factors. Webtrax aggregates successive hits from the same IP address within a configurable period of time into a "visit."
Caching at the user's browser. A browser may display a page or image to an end user without going over the web at all.
Caching at a network proxy. AOL, for example, caches pages, images, and applets somewhere between your server and the end user. The server sees far fewer hits than you might expect, and if you combine all the AOL hits together (as you might with the webtrax "pre_domain" mapping), then the resulting user's path through the site appears to jump around.
Other proxy behavior. For example, if a visitor from Microsoft visits your pages, the server logs a whole cloud of hits from multiple different IPs, but it's all the same user.
Web server behavior writing the log. Some web servers may discard log events in order to keep up at times of heavy load. If the disk partition where the log resides becomes full, the web server may keep serving pages but skip writing the logs. Log entries may not be written in the order that requests were issued from the end user: I have seen cases where the log entry for a graphic linked by a page occurs before the page's entry.
Client bugs. Some browsers, crawlers, and web apps send HTTP requests that are not in the standard form. Referrer and client information may be missing, spoofed, or incorrect.
Webtrax was originally written by John Callender and has been substantially enhanced by Tom Van Vleck. Paul Schmidt contributed the preprocessing feature, some additional search engine strings, and a feature to allow default visit classes based on directory. ![]() Ned Batchelder contributed a fix to DNS cache processing, and two new commands.
Ned Batchelder contributed a fix to DNS cache processing, and two new commands. ![]() Simon Child has also contributed bug fixes, and
Simon Child has also contributed bug fixes, and ![]() Ben Eden has suggested multiple useful improvements.
Ben Eden has suggested multiple useful improvements.
Weaknesses of the program
Like any program that has grown incrementally over more than ten years, Webtrax has its share of mistakes and problems, choices I'd make differently if writing a new program from scratch. The large number of options (over 80) and their inconsistent naming is an embarrassment. The non-modularity of the program made sense when it was little, but by now it is a problem that inhibits further enhancements. The intertwining of HTML and non-HTML output clutters the code. Non-HTML mode is an example of a feature I don't use and don't test, so it may be broken. If I were to start fresh, I would experiment with loading the log into a database and then writing a report generation engine. Perl has been a wonderful tool for writing Webtrax but it has been used in a low-level way and its performance and memory consumption are drawbacks. Still, Webtrax is "good enough" for my use, and writing or finding a better tool is not a high priority for me. I hope others will find it useful, with all its faults.
Output
Webtrax can produce the following output sections:
- Heading
- Navigation links, if html mode
- Optional preamble copied from a text file (Option: $preamble )
-
Visits / MB / hits / page loads
by day for last N days.
(Option: $summary_lines
)
Highest numbers in this listing are colored red, lowest blue.

-
Analysis
(Options: $show_analysis
$javapie
)
- Pie chart: Hits by file type.
-
Pie chart: Visits by hit type
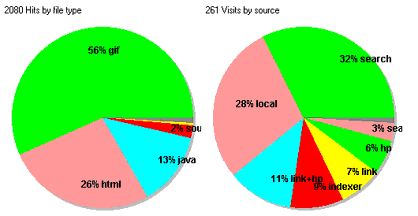
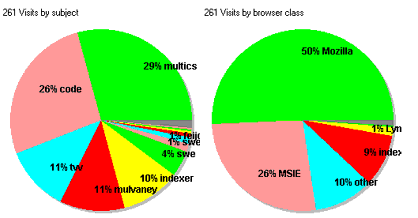
- Pie chart: Visits by visit class
-
Pie chart: Visits by browser class
(Option: $wars
)
- Pie chart: Visits by platform (no picture yet)
-
Hit and visit statistics:
HTML pages,
head pages,
search engines,
indexers,
visits with no html,
links
(Options: $robot
$robotdomain
$headpage
)

-
Accesses by file type
-
Stacked bar chart: Hits caused / KB caused / Hits
by html page by hit type
(Options: $count_pages
$nshowpages
$hotlink_html_prefix
$show_directories
)

- Summaries of other file types and hits. (Options: $count_gifs $count_pngs $count_jpegs $count_css $count_downloads $count_sounds $count_javas $count_cgis $count_othe $show_directoriesr )
- Summary of missing file pathnames (Options: $count_notfound $show_directories )
-
Stacked bar chart: Hits caused / KB caused / Hits
by html page by hit type
(Options: $count_pages
$nshowpages
$hotlink_html_prefix
$show_directories
)
- Summary of illegal references: Hits / KB by referring page showing what object was referenced (Option: $show_illegal_refers )
-
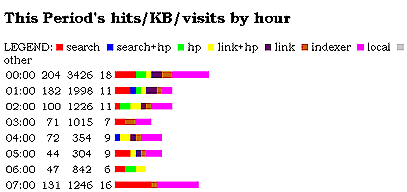
Stacked bar chart: Hits / KB / Visits by hour by hit type
(Option: $show_histogram
)
- Bar chart: Visits / KB / Hits by toplevel domain (Options: $show_tldsum $nshowtopleveldomains )
- Bar chart: Visits / KB / Hits by domain (Option: $nshowbusydomains )
- Bar chart: Cumulative Visits / KB / Hits by page this year (Options: $show_cum $nshowbusycumpages $hotlink_html_prefix $show_directories )
- Bar chart: Cumulative Visits / KB / Hits by toplevel domain this year (Options: $show_cum $nshowcumtldvisits )
- Bar chart: Visits / KB / Hits by visit class (Options: $class $show_class $nshowclasshits )
- Bar chart: Visits / KB / Hits by browser (Options: $show_browser $nshowbrowserhits )
- Bar chart: Visits / KB / Hits by query (Options: $show_query $nshowqueryhits )
- Bar chart: Visits / KB / Hits by referring page (Options: $show_referrer $nshowreferrerhits )
- Bar chart: Cumulative Visits / KB / Hits by referring page this year (Options: $show_referrer_hist $nshowcumreferrers $cumulate_search_terms )
- Bar chart: Visits / KB / Hits by search engine (Options: $show_engine $nshowengine )
- Table: Transactions/KB by server return code (Option: $show_retcodes )
- Table: Transactions/KB by protocol verb new (Option: $show_verbs )
- Visit Details including date and time, pages visited, time between pages, query and referring site, total hits and bandwidth, and user agent. (Options: $show_visit_list $min_details_session $show_indexer_details $show_each_hit $inred $filedisplay $rettype $show_browser_in_details )
- Optional postamble copied from a text file (Option: $postamble )
- Navigation links, if html mode
Installation Instructions
- Copy webtrax.tar.gz.
-
Unzip it
gunzip webtrax.tar.gz -
Untar it
tar -xf webtrax.tar(These are UNIX commands. Stuffit Expander will open the file up for Windows or Macintosh.)
This will create
- webtrax.pl (Perl program)
- logextractor (Perl program)
- webtrax.rc (Configuration file)
- public_html/redpix.gif (for HTML output)
- public_html/yellowpix.gif
- public_html/bluepix.gif
- public_html/greenpix.gif
- public_html/purplepix.gif
- public_html/orangepix.gif
- public_html/graypix.gif
- public_html/pinkpix.gif
- public_html/Pie.class
- public_html/PieItem.class
- public_html/PieView.class
One good way to arrange things is to put the gif files and the .class files in an unlinked directory (possibly password protected) in your web space. Do your log processing in a second directory outside the web space and move your HTML report into the first directory once a day.
-
Edit webtrax.rc to set
- Your site name in the $site_name option.
- Your site URL in the $kill_referrer option.
- Other options as desired.
Usage
perl5 webtrax.pl [webtrax.rc] [log files...]
If a file name given on the command line has the suffix .rc it is processed as a configuration file. Other file names are those of log files. They are processed in order. If any log file name ends with ".gz", ".z", or ".Z", the file will be read through zcat to unzip it. ( updated On some systems such as Mac OS X, zcat fails unless the compressed file ends in .Z. If so, use gunzip -c. Or install a better zcat using Fink. Thanks to Stephen Proulx for the bug report.) With no arguments, webtrax looks for configuration file webtrax.rc and then processes the one file httpd_access.0.
I run this program from a daily cron job. Use
crontab filename
to set it up, with the file "filename" containing something like the following line:
47 8 * * * $HOME/runwebtrax.sh
This will run a report at 8:47AM every day. See the sample shell script below.
Webtrax requires perl5. (Perl4 doesn't do double indexing.)
Contents of the .rc file
The options and values described above can be set by modifying text lines in the .rc file. At the very least, you should set up your own title for the report by including a statement like
$site_name = "Joe's Web Site";
Each line in the configuration file has the form
$option = "value";
and these settings override the defaults. Webtrax is unforgiving about spacing. the dollar sign goes in column 1, there must be spaces around the equal sign, and the quotes and semicolon are required, or the line will be silently ignored. Comments in the .rc file begin with # and end with the end of the line.
See the sample .rc file below.
Domain Name Translation Controls
(Options: $do_reverse_dns $dnscache_file $do_geoip $geoip_file )
Program Output
(Options: $output_file $mailto_address )
Referrers
If the log being processed includes the referrer string, this indicates what page the browser was looking at when it generated your hit. If the hit was generated by a search engine, the query may be included in the referrer string. Webtrax uses the referrer string to drive a lot of its analyses.
Treating Certain Referrers as local
(Option: $kill_referrer )
How can a visit be "local?"
If what appears to be a visit starts with a hit referred by a local page, this may be a sign that the user is accessing the site very slowly, or that the user is accessing your site through a proxy that uses more than one address (microsoft.com seems to do this). Some web servers seem to put hits in their logs out of order, and this may also cause this. I have set the default expire_time up to 30 minutes, and still see a lot of these on my site. Visits that begin with a "local" hit are marked with "*" in the visit details.
Ignoring certain Domains
Many people have asked to be able to ignore their own hits on their site. (Option: $ignore_hits_from )
Toplevel Domains
By default, webtrax summarizes hits by toplevel domain, e.g. ".com". For toplevel domains that correspond to a country, the country name is shown. (Option: $special_domain )
Remapping File Names, Domains and Referrers
The $pre_url, $pre_referrer, $pre_domain and $pre_file options may each appear multiple times. Each instance contains a Perl substitute command which is applied to the url, referrer, domain name, or referenced file pathname. These items are useful for treating several files as a single file, mapping multiple forms of a referrer URL into a single value, etc. When $show_directories is set, there may be some directories that you wish to hide the name of, and this feature will allow that too. If $show_directories is set and if your log contains mixed references via a custom domain and by regular user name (e.g. ~thvv) this feature can be used to map the two into one. If $show_directories is not set, you may have multiple subdirectories each with an index.html that you wish to distinguish; you can do this with a statement like
$pre_file = "s/jax\/index\.html/jax_index.html/";
(Options: $pre_url $pre_referrer $pre_domain $pre_file $show_directories )
Return Code Summary
Webtrax can show a table of all transactions logged by the web server, organized by return code. Most of the transactions will have code 200; but code 304 means that a distant proxy was checking to see if the file had changed, so it also counts as a hit. Code 206 means that part of the file was returned; a big file might be requested in chunks. Currently webtrax counts all of these transactions as hits, since it can't tell which partial content answers are part of the same request. Other return codes are counted but their transaction is not considered a hit. The "rettype" command can be used to indicate which commands are hits: a type of 0 is a non-hit, a type of 1 is a hit, and a type of 2 is a non-hit that is still put in the visit details listing. The "rettype" command can also specify the CSS class for a hit in the visit details section.
(Option: $rettype )
$rettype = "304:2:cac";
There was a bug in Webtrax prior to V23 when dealing with log records for transactions returning code 304 if the web server logged the length as "-". Webtrax was ignoring these hits. This problem has been corrected. updated
Platform Summary
Webtrax can show a chart of total accesses by platform, that is, by operating system. This chart matches patterns against the referrer string sent by the browser and is not 100% accurate (browsers misrepresent themselves). To declare the patterns, add any number of options like the following:
$platform = "Win95";
$platform = "Win98";
$platform = "WinNT";
$platform = "Win32";
$platform = "Win2000";
$platform = "WinMe";
$platform = "WinXP";
$platform = "Windows";
$platform = "Mac";
$platform = "Linux";
$platform = "FreeBSD";
$platform = "IRIX";
$platform = "SunOS";
$platform = "OS/2";
A special hack replaces "Windows " by "Win" when determining the platform, because browsers are inconsistent in their reporting.
(Option: $platform )
Search Engines and Queries
Webtrax detects some queries as coming from search engines. Many popular engines are built in. You can add to the builtin engines by adding options to the .rc file of the form
$query = "lycos?http:\/\/.*lycos.*\/cgi-bin\/pursuit?query=([^&]+)";
in which the three parts (name, detector, and query extractor) are specified separated by question marks. The second two are regular expressions with literal characters backslashed.
It's a little tricky: webtrax matches the detector against a downcased name but the query extractor is exact case.
If a hit's referrer has a "query portion" (after a question mark) but none of the query detectors match, Webtrax will assume it's a query from a search engine and make a guess about the query field. If a hit's filename has a "query portion," Webtrax will also assume it's a query on the local site and make a guess about the query field.
(Option: $query )
Visit classification
Visit classification works like this: specify one or more "classes" for your pages by adding options of the form
$class = "pagename:class1,class2,class3";
to your webtrax.rc file. Webtrax will then examine the sequence of hits and classify the visit according to the kinds of pages visited. (Hits from web indexers are classified automatically as 'indexer'.) The commas represent pages that could fall into more than one category. Webtrax will attempt to choose the most appropriate class for a visit. For example, if page a.html is classified class1,class2 and page b.html is classified class2, then a visit that references both should be classified just "class2". If a.html were classified only class1, then the visit would be classified "class1>class2". If you don't use this feature you don't get the report.
(Option: $class )
Paul Schmidt contributed an elegant extension. If you say
$class = "/dirname/:foo";
(that is, the name ends in a slash) and if a page in directory "dirname" has no other class assigned, it will be given class foo. Use
$class = "/:bar";
to supply a default class for files in your base directory.
Option Documentation
(may be specified multiple times)
Specify one or more classes for your pages, so that visit classification can be done.
Default value: ""
Output report showing notfound accesses.
Default value: "yes"
Output report showing *.au/mp2/wav accesses.
Default value: "no"
new Remember search terms in cumreferrer.hit. This will make the file a lot bigger and the long-term referrer listing longer.
Default value: "yes"
Look up numeric domains to obtain a country code. See geoip.
Default value: "no"
Translate numeric URLs in the input into names. Some log files have this done already, or you can use logextractor to do this. This process can be time consuming, so Webtrax attempts to do it only once. If you specify a dnscache file, then Webtrax will remember lookups from one run to another. Trim this file occasionally.
Default value: "no"
Set which file extensions are downloads.
Default value: "exe\$\|zip\$\|z\$\|hqx\$\|sit\$\|pdf\$"
Elapsed time between accesses (in seconds) until a "visit" ends.
Default value: "1800"
(may be specified multiple times)
In the visit details section, specify a CSS class for specific filenames.
Default value: ""
GEOIP CSV file name for do_geoip.
Default value: "GeoIPCountryWhois.csv"
Report on what percentage of your hits and visits came from designated head pages. You can tell it what a head page is.
Default value: ""
Hyperlink the site file names in the accesses by file type and cumulative hits by page tables, prefixing its link with the supplied value, which may be "" or a value to account for the location of the report, such as "..".
Default value: "yes"
Set which file extensions are considered HTML.
Default value: "html\$\|htm\$\|shtml\$\|cgi\$\|html-ssi\$\|asp\$\|pl\$\|php\$"
(may be specified multiple times)
ignore all hits from this domain. You may wish to put in IP numbers as well in case the log entry specifies a number instead of a name, which happens sometimes if a log extractor's reverse name lookup stops working.
Default value: ""
(may be specified multiple times)
In the visit details section, specify that specific filenames be shown in the CSS class "inred". See "filedisplay".
Default value: ""
new Show Java pie charts in the HTML report. If Java doesn't work for you, turn this flag off and you will get a textual representation of the data. Uses the Java classes Pie, PieItem, and PieView to display pie charts.
Default value: "yes"
(may be specified multiple times)
The summary by referrer should ignore references from one page at your site to another. Specified arguments are matched against the lowercased referrer value. You don't need to backslash slashes in your string. You can include any number of these options, to treat multiple sites as local, e.g. with and without www..
Default value: ""
Name of the default input log file.
Default value: "httpd_access.0"
Location of system's mail program.
Default value: "/usr/sbin/Mail"
Set to one or more email addresses (separated by spaces within the double quotes), webtrax will mail its output file to the given address(es). Leaving $mailto_address empty turns off this feature. Be sure to put a backslash in front of the @ symbol.
Default value: "none"
new In the visit details section, suppress display of visits with fewer hits.
Default value: "1"
Set which file extensions are omitted from cumpage.
Default value: "gif\$\|jpg\$\|png\$\|au\$\|mp2\$\|mp3\$\|wav\$\|css\$\|swf\$"
Set which file extensions are omitted from visit details.
Default value: "gif\$\|jpg\$\|png\$\|au\$\|mp2\$\|mp3\$\|wav\$\|css\$\|swf\$|ico\$"
Number of today's browser hits to show.
Default value: "10000"
Number of busy pages to show longterm.
Default value: "10000"
Number of today's busy (full) domains to show.
Default value: "10000"
Number of cumulative visits by referrer to show.
Default value: "10000"
Number of number of cumulative visits by tld to show.
Default value: "10000"
Number of today's referrer hits to show.
Default value: "10000"
Number of today's toplevel domains to show.
Default value: "10000"
Name of the output file. If you give $output_file an .html extension, Webtrax will create an htmlized version of the report, setting permissions on it to 644 (world readable).
Default value: "index.html"
(may be specified multiple times)
Platform names to summarize in the platform pie chart.
Default value: ""
File copied in at bottom of HTML report.
Default value: "none"
(may be specified multiple times)
Transformation applied to each domain name before use.
Default value: ""
(may be specified multiple times)
Transformation applied to each filename before use.
Default value: ""
(may be specified multiple times)
Transformation applied to each referrer before use.
Default value: ""
(may be specified multiple times)
Transformation applied to each argument to GET before splitting out query and pathname.
Default value: ""
File copied in at top of HTML report.
Default value: "none"
(may be specified multiple times)
new Whether a given retcode is a hit and what CSS class to display it in.
Default value: ""
Site URL linked from heading html report.
Default value: "none"
(may be specified multiple times)
User agents that are treated as web indexers.
Default value: ""
(may be specified multiple times)
new Declare all hits from a particular domain to be from a web indexer.
Default value: ""
(may be specified multiple times)
Search engine detector and query extractor. Specify three fields: the engine name, the recognition regexp, and the query extraction regexp. Hits whose full filename matches the detection regexp will then be matched against the extraction regexp and $1 will be identified as the query.
Default value: ""
Output derived figures, including pie charts and a table of summary numbers.
Default value: "yes"
In the visit details section, show the browser for each visit.
Default value: "no"
Keep long term statistics and output bar charts showing cumulative hits by page and by TLD.
Default value: "yes"
Display directory names in visit details and filename reports.
Default value: "no"
In the detail listing, show the name of each HTML page hit. Turn this off to have each visit represented by a one line summary.
Default value: "yes"
Output a tabular report of illegal referrers.
Default value: "yes"
In the visit details report, show visits by indexers. Turn this off to suppress these visits.
Default value: "yes"
Output a bar chart of referrers long term.
Default value: "yes"
Output a tabular report of all transactions logged by the web server, organized by return code. Most of the transactions will have code 200; but code 304 means that a distant proxy was checking to see if the file had changed, so it also counts as a hit. Code 206 means that part of the file was returned; a big file might be requested in chunks. Currently webtrax counts all of these transactions as hits, since it can't tell which partial content answers are part of the same request. Other return codes are counted but their transaction is not considered a hit. The "rettype" command can be used to indicate which commands are hits: a type of 0 is a non-hit, a type of 1 is a hit, and a type of 2 is a non-hit that is still put in the visit details listing. The "rettype" command can also specify the CSS class for a hit in the visit details section..
Default value: "yes"
Output a bar chart showing usage by top level domain.
Default value: "yes"
new Output a tabular report of all transactions logged by the web server, organized by protocol verb. Most of the transactions will be GET transactions; POST transactions are used by some CGI programs. Other requests, not counted as hits, include HEAD, used to check the date modified of a file, and PUT and PROPINFO, used by WebDAV.
Default value: "yes"
Set which file extensions are sounds.
Default value: "au\$\|mp2\$\|mp3\$\|wav\$"
Set which file extensions are sourcefiles.
Default value: "c\$\|h\$\|makefile\$\|java\$\|cpp\$\|pl\$"
(may be specified multiple times)
Treat certain domains as if they were toplevel.
Default value: ""
Number of days to summarize, ie days in a month.
Default value: "31"
(may be specified multiple times)
Browser names to summarize in the browser pie chart.
Default value: ""
Definition of Terms
- hit
-
Each file transmitted by the server to a browser is logged by the web server as a "hit." For example, if a user visits an HTML page that refers to three GIFs and a Java applet would count as five hits, one for the HTML page, three for the GIFs, and one for the applet. (Assuming the user has Java enabled and is loading images.) Webtrax can be told to ignore certain hits in various ways.
(Options: $ignore_hits_from $rettype )
- visit
-
If there is a sequence of hits from the same domain, these are counted as a single visit. If the hits stop for longer than a certain idle time, and then start again, Webtrax will see two visits. You can configure the length of the idle interval by changing $expire_time; by default it's 30 minutes. (See "How can a visit be 'local?'" above.)
(Option: $expire_time )
- page
-
For comparing website activity, HTML page loads are more interesting than hits. You can set option $html_types to a regular expression that selects the suffixes which count as HTML pages. The default is "html$|htm$|shtml$|cgi$|html-ssi$|asp$".
(Option: $html_types )
- caused
-
These columns attempt to detect which pages are responsible for the most hits and data transfer.
- hit type
-
Each hit is classified as to its type; a hit may be on a head page, the result of a link to head page, the result of a search that found the head page, the result of some other link, the result of some other search, generated by a web indexer, or unspecified.
(Options: $headpage $robot $robotdomain )
- engine
-
Search engines are detected by looking at the referring page, which has the URL of the search engine's page, and often the query used to search.
- query
-
When a hit appears to come from a search engine, Webtrax tries to see what the engine was searching for. It can't always extract the query; some engines, like Gamelan, don't put the query term in the referring URL, and in these cases Webtrax doesn't show a query. See Search Engines and Queries above.
(Option: $query )
- head
-
Head pages are declared in the .rc file by specifying one or more $headpage options.
(Option: $headpage )
- Link
-
Other users' pages can have hyperlinks to yours. If the person browsing your site uses a browser that sends the referrer info, and if your web server puts that information in the log, you can see who links to you and how often those links are used. Webtrax will summarize the number of links to your pages.
- illegal
-
An illegal hit is a reference to an object on your site (not a source file) from a referrer that is not a source file on your site. (The option $sourcefile_extensions determines what are source files.) One cause for this is people linking to your graphics from their pages. Another possible cause is an incorrect referrer string sent by a browser.
(Option: $sourcefile_extensions )
- Visits with no HTML
-
Visits that do not reference any source files are summarized separately. Such visits may result from web crawlers that look only at graphics files or PDF files, or from illegal references to your graphics from others' sites, or from a reference to a graphic, PDF, or whatever on your site in a mail message. These visits are not shown in the visit details section.
- Domain
-
Each hit comes from a machine identified by its Internet domain name like barney.rubble.com. If the domain cannot be identified by name, its IP Number is shown. If geoIP processing is enabled, and the name cannot be found, the IP will have a country name suffix in brackets.
(Options: $do_reverse_dns $dnscache_file $do_geoip $geoip_file )
- Toplevel Domain
-
Toplevel domains are the least specific part of the name, like .com or .de. You can treat a more specific domain name as a toplevel domain by using the $special_domain option. If a log entry comes from an domain with all numeric entries, Webtrax will attempt to look up the name of the site if $do_reverse_dns is specified and the dnscache file name is given. Webtrax will attempt to look up the country code for the IP address if $do_geoip is specified and the geoIP file is provided. If the domain is still all numeric, it is identified in the log as "numeric."
(Options: $special_domain $do_reverse_dns $do_geoip )
GeoIP processing looks up numeric domains in a CSV file to obtain a country code. To use this feature, you must download the data file GeoIPCountryWhois.csv. It is available free from
 maxmind.com.
maxmind.com.
- it's only invoked on numeric IPs.
- some numeric IPs are not listed in the data file.
- for the IPs found in the file, the detail listing will show the IP suffixed by the looked up country code, e.g. 210.68.176.9[tw] and will total it correctly in the TLD listing.
- if given a numeric IP, and both webtrax's reverse DNS and geoIP work, and if the TLD from reverse DNS doesn't match the geoIP country, then the TLD is set to something like ".com[us]"
When you turn the geoIP feature on, Webtrax reads the whole table into memory in order to look up IP addresses rapidly. This extra memory usage may cause Webtrax to use excessive memory resources for some shared server environments. You can perform the reverse DNS and geoIP processing in a separate step using the logextractor program before running Webtrax to avoid this problem.
- Cumulative
-
Webtrax accumulates some statistics for a period longer than a day. You can reset these statistics by deleting the files
cumtld.hit cumpage.hit cumreferrer.hit
The cumpage.hit can get pretty big; it is a good idea to remove all the lines ending in ",1" every so often. (Some file suffixes are ignored in cumpage.hit. You can change the option $nocumpage_extensions to affect which file suffixes are ignored.)
(Options: $show_cum $nocumpage_extensions )
- Indexers
-
Search engines work by reading your pages and building a big index on disk. When they do this it creates a sequence of hits. Webtrax will count these separately if you tell it the names of the search engines' indexers or domains, and if the browser (user agent) name is provided in the log. You can suppress these indexer visits from the visit details by setting an option, described below; if the hits are displayed, they are in the CSS class "indexer", which a custom style sheet can decorate.
(Options: $robot $robotdomain $show_indexer_details $stylesheet )
- Visit Details
-
(Options: $show_visit_list $min_details_session $show_indexer_details $show_each_hit $inred $filedisplay $rettype $show_browser_in_details $class )
This listing is enabled by the $show_visit_list option. Option $min_details_session suppresses visits with fewer than the specified number of pages: the default is 1. new Option $show_indexer_details, if set to "no", suppresses visits by indexers.
Here is an example listing:
16:38 xxx01.xxx.net -- g.html (gamelan:-) 0:01, ga.class 2:25, gv.class [4, 212 KB; MSIE 5.3] {code}For each visit, Webtrax shows
-
Time of the visit.
If $show_each_hit is "yes", the following are shown:
- A double hyphen (--)
- Names of pages visited. GIF files, sounds, etc. are not shown. (You can change the option $nodetails_extensions to affect which file suffixes are ignored.) Files whose path matches an $inred option will have their names shown in the CSS class "inred", which displays in red in the default stylesheet. Files whose path matches a $filedisplay option will have their names shown in a specified CSS class. new (Using this feature requires that you use a custom CSS file set with the $stylesheet option.) If the $rettype option is used to specify that transactions with a given server return code are to be shown in a CSS class, the class will be applied. $rettype overrides $inred or $filedisplay. The classes "fnf" (gray) and "cac" (pink) are in the built-in style sheet; others can be provided in a custom style sheet. new
- For all but the last page reference, the time between references (in mm:ss format).
- If a reference came from an external page, the referring page URL in parentheses. This URL will be made a clickable hyperlink if it looks like doing so would work; it will be colored red the first time webtrax sees this referrer. If this is a search engine query, the query parameters will be shown in the URL in green.
- The number of hits and the number of KB transferred for this visit, in square brackets. If $show_browser_in_details is true, the browser name is included.
- If the visit classification feature is being used, the classification of the visit in braces.
-
Time of the visit.
If $show_each_hit is "yes", the following are shown:
- class
-
You can specify what "class" each page is in. Then visits are classified by whether they examined only pages in one class, or more classes.
(Option: $class )
Report Formatting
The HTML report is formatted using a built-in style sheet unless you specify the $stylesheet configuration item. If no style sheet is specified, the following definitions are used:
<style>
dt {float: left} /* detail report */
dd {margin-left: 40px} /* detail report */
.navbar {font-size: 80%;} /* navigation links */
.chart {} /* bar charts */
.monthsum {} /* month summary */
.analysis {} /* analysis by day */
.brow {} /* browser name */
.vc {} /* visit class */
.sessd {} /* session details */
.pie {} /* pie chart formatting */
.indexer {} /* session by an indexer */
.fnf {color: gray;} /* file not found */
.cac {color: pink;} /* cached */
.fbd {color: green;} /* forbidden */
.filetype {font-size: 80%;} /* file types by name */
.illegal {} /* illegal referrer report */
.refdom {font-weight: bold;} /* referencing domain or IP */
.newref {color: red;} /* color for first time referrer */
.inred {color: red;} /* file names matching "$inred" */
.max {color: red;} /* highest value in month summary */
.min {color: blue;} /* lowest value in month summary */
.query {color: green;} /* query text in detail report */
.details {font-size: 80%;} /* detail report */
td {padding-top: 0; padding-bottom: 0;
margin-top: 0; margin-bottom: 0;
border-top-width: 0; border-bottom-width: 0;
line-height: 90%;} /* each row in bar charts */
body {background-color: #ffffff; color: #000000;}
</style>
Extracting Logs
The program logextractor is supplied with webtrax. It reads an NCSA [combined] web server log and extracts a day's worth of data. It optionally does reverse DNS lookup on numeric IPs. It also optionally does geoIP lookup on numeric IPs, and Webtrax will accept domains with the geoip lookup already done.
logextractor [-dns cachefile] [-geoip geoipfile] -day mm/dd/yyyy filepath ... > outpath logextractor [-dns cachefile] [-geoip geoipfile] -day yyyy-mm-dd filepath ... > outpath logextractor [-dns cachefile] [-geoip geoipfile] -day yesterday filepath ... > outpath logextractor [-dns cachefile] [-geoip geoipfile] -day all filepath ... > outpath
Finds all log entries that occurred on the given day and writes them to stdout.
Sample .rc file
# webtrax.rc file example # $site_name = "Joe's Web Site"; # site name for the report $log_file = "httpd_access.0"; # name of the input log file $output_file = "report.html"; # name of the output file $return_URL = "index.html"; # URL to return from html report $preamble = "report.ins1"; # file inserted in report near the top $postamble = "report.ins2"; # file inserted in report near the bottom $mailto_address = ""; # email address for mailed report $mail_program = "/usr/sbin/Mail"; # location of your system's mail program $summary_lines = "31"; # number of webtrax runs to summarize $expire_time = "900"; # elapsed time until "visit" ended $show_directories = "no"; # display paths with filenames $count_pages = "yes"; # count *.html accesses $count_gifs = "no"; # count *.gif accesses (not in details section) $count_pngs = "no"; # count *.png accesses (not in details section) $count_jpegs = "no"; # count *.jpg accesses $count_csss = "no"; # count *.css accesses $count_downloads = "yes"; # count *.exe/zip/Z/hqx/sit/PDF accesses $count_sounds = "no"; # count *.au/mp2/wav accesses $count_javas = "yes"; # count *.class accesses $count_cgis = "no"; # count *.cgi accesses $count_other = "yes"; # count other accesses $count_notfound = "yes"; # count notfound accesses $show_histogram = "yes"; # show when sessions started $show_tldsum = "yes"; # summarize by top level domain $show_cum = "yes"; # keep long term stats $show_referrer = "yes"; # show interesting referrers in details $show_browser = "yes"; # show report by browser $show_browser_in_details = "yes"; # tag each detail report with browser name $show_class = "yes"; # show report by class $show_engine = "yes"; # show report by search engine $show_query = "yes"; # show report by query string $show_visit_list = "yes"; # show list of visits $show_each_hit = "yes"; # show each file in a visit $show_illegal_refers = "yes"; # report on links to non-html $show_analysis = "yes"; # show derived figures $show_retcodes = "no"; # report on transactions by server return code $show_verbs = "no"; # report on transactions by protocol verb new $show_indexer_details = "yes"; # if YES, show sessions by indexers $min_details_session = "1"; # show visits with at least this many pages new $do_reverse_dns = "no"; # if YES, translate numeric domains to names $dnscache_file = ""; # if nonblank, pathname of the DNS cache file $do_geoip = "no"; # if YES, look up numeric domains to determine TLD geoip_file = "GeoIPCountryWhois.csv"; # pathname of the geoip input file $show_referrer_hist = "yes"; # show cumulative referrer history $kill_referrer = "http://www.best.com/~jb/"; # don't show this site as a referrer $ignore_hits_from = "kip.saturn.sun.com"; # completely ignore hits from this site $special_domain = ".aol.com"; # treat this domain as if top level $special_domain = ".compuserve.com"; # .. this too $nshowpages = "30"; # number of today's HTML pages to show $nshowbrowswerhits = "10000"; # number of today's browser hits to show $nshowtopleveldomains = "10000"; # number of today's toplevel domains to show $nshowbusydomains = "30"; # number of today's busy (full) domains to show $nshowqueryhits = "10000"; # number of today's query hits to show $nshowreferrerhits = "10000"; # number of today's referrer hits to show $nshowengine = "10000"; # number of today's engines to show $nshowbusycumpages = "20"; # number of busy pages to show longterm $nshowcumtldvisits = "20"; # number of cumulative visits by tld to show $nshowcumreferrers = "30"; # number of cumulative referrers to show $max_referrer_length = "32"; # trim referrer to this length in report $max_query_length = "32"; # trim query to this length in report $max_browser_length = "32"; # trim browser to this length in report $max_domain_length = "255"; # trim domain to this length in report $cumulate_search_terms = "yes"; # remember search terms in cumreferrer.hit new $javapie = "yes"; # do Java pie charts in HTML mode new $rettype = "302:1"; # say you wanted to count 302s as a hit $rettype = "404:2:fnf"; # list 404s in the details, in class "fnf" new $nodetails_extensions = "gif$|jpg$|au$|mp2$|mp3$|wav$|css$|ico$"; # which files are omitted from details updated $nocumpage_extensions = "gif$|jpg$|au$|mp2$|mp3$|wav$|css$"; # which files are omitted from cumpage $sound_extensions = "au$|mp2$|mp3$|wav$"; $download_extensions = "exe$|zip$|z$|hqx$|sit$|pdf$"; $sourcefile_extensions = "c$|h$|makefile$|java$|cpp$|pl$"; $stylesheet = "mystyle.css"; # optional style sheet $headpage = "jb.html"; $headpage = "index.html"; # delcare certain user-agents to be robots $robot = "Slurp"; $robot = "ArchitextSpider"; $robot = "Scooter"; $robot = "Lycos_Spider"; $robot = "Netscape-Catalog-Robot"; $robot = "ia_archiver"; # Declare certain domains to be robots $robotdomain = "crawler.looksmart.com"; new # $pre_file = "s/index.cgi/index.html/"; $pre_domain = "s/cache-.*\.proxy\.aol\.com$/cache-x.proxy.aol.com/i"; $pre_referrer = "s/index.cgi/index.html/"; $pre_url = "s/\/go.php[?]to=(.*)/go:\1/"; # preprocess URL for exit pages # tag some domains with who they are $pre_domain = "s/(dsl202-...-...\.kc\.dsl\.example\.net)/!Sally $1/i"; # $inred = "resume-long.html"; $filedisplay = "inred,specialfile.html"; new # $wars = "MSIE"; $wars = "Mozilla"; $wars = "Lynx"; $wars = "Java"; # $class = "jb.html:jb"; # defines two classes $class = "index.html:jb,animals"; # this page might be either $class = "changes.html:animals"; $class = "rats.html:animals,jb"; $class = "cats.html:animals,jb"; $class = "resume.html:jb"; $class = "recipes.html:jb"; # $platform = "Win95"; $platform = "Win98"; $platform = "WinNT"; $platform = "Win32"; $platform = "Win2000"; $platform = "WinMe"; $platform = "WinXP"; $platform = "Windows"; $platform = "Mac"; $platform = "Linux"; $platform = "FreeBSD"; $platform = "IRIX"; $platform = "SunOS"; $platform = "OS/2"; # # end
Sample Shell Script for use with cron
#!/bin/sh
# Shell script run by cron every day to create website usage report.
# If all goes well, this script says nothing.
# cron will send me mail with any error message.
#
# this script keeps only the last just-processed log and deletes the rest.
#
# Define the following variables as absolute paths before running.
# Remember that cron jobs do not have your standard shell environment.
#
# $WHEREISPPUTSLOGS .. Where the ISP puts your raw logs
# $WHERETOPUTREPORT .. where to put "report.html"
# $PROCESSINGDIR .. where you keep webtrax history files
# $WTPROGDIR .. where you keep webtrax, logextractor, webtrax.rc
#
# 12/16/04 THVV
#
export WHEREISPPUTSLOGS="/usr/home/you/www_logs"
export WHERETOPUTREPORT="/usr/home/you/html/secretplace"
export PROCESSINGDIR="/usr/home/you/webtraxstuff"
export WTPROGDIR="/usr/home/you"
#
cd $WHEREISPPUTSLOGS
# do all the logs (in random order)
for i in www.*
{
if test "www.*" = $i
then
# if the wildcard doesn't match anything, it runs once with "www.*"
echo "logs missing"
else
# save the old reports
cd $WHERETOPUTREPORT
mv report.0.html report.1.html
mv report.html report.0.html
# move the logfile into the processing directory
cd $WHEREISPPUTSLOGS
mv $i $PROCESSINGDIR
# back work files up in case of problems
cd $PROCESSINGDIR
cp summary.txt summary.0.txt
cp cumtld.hit cumtld.hit.0
cp cumpage.hit cumpage.hit.0
cp cumreferrer.hit cumreferrer.hit.0
#
# extract hits from log and process with geoip
# .. assuming your ISP has already extracted a day's logs from the master log
nice $WTPROGDIR/logextractor -day all -geoip GeoIPCountryWhois.csv $i > templog
#
# generate the report
nice perl $WTPROGDIR/webtrax.pl $WTPROGDIR/webtrax.rc templog
#
if test -r report.html
then
rm templog
# generate the detail report for failures
if test -r www.*.gz
then
zgrep -v " 200 " $i | egrep -v " 206|302|304 " > report.txt
mv $i httpd_access.0.done.gz
else
egrep -v " 200|206|302|304 " $i > report.txt
mv $i httpd_access.0.done
rm -f httpd_access.0.done.gz
gzip httpd_access.0.done
fi
# move the report to the web directory
chmod 644 report.txt report.html
mv report.txt report.html $WHERETOPUTREPORT
else
echo "*** $i failed, put log back"
mv $i $WHEREISPPUTSLOGS
mv summary.0.txt summary.txt
mv cumtld.hit.0 cumtld.hit
mv cumpage.hit.0 cumpage.hit
mv cumreferrer.hit.0 cumreferrer.hit
cd $WHERETOPUTREPORT
mv report.0.html report.html
mv report.1.html report.0.html
fi
fi
}
# end
Copyright (c) 2002-2023 by Tom Van Vleck