The New Storage System project picked up a whole commercial operating system, dug a new basement, and set the system down on top of it without breaking a dish. Here is how we did it.
The Problem
In the initial design of the Multics file system, disk addresses were assigned in increasing order, as if all the drives of a given device type made up one big disk. We didn't think a lot about this approach, it was just the easiest. One consequence of this address policy was that files tended to have their pages stored on multiple disk drives, and all drives were utilized about equally on average.
A major simplification of page control about 1968 was to store the disk address for a page not in core in the address field of the faulted PTW (Page Table Word). This limited us to 18 bits for a disk address. As disk became cheaper and more plentiful, and the storage capacity of Multics systems grew, we ran out of space in the PTW address field. The maximum disk capacity of a Multics system was 28 DSS191 units (75 MB each). Higher capacity disks were becoming available and users wanted to add more storage to their Multics sites.
The original design also didn't anticipate removable pack disk drives, like the IBM 2311 and 2314, supported on OS/360. Users wanted to use these drives, so that they could dismount storage for safekeeping or to access other data.
Another consequence of the original design was that the crash of a single drive required all drives to be reloaded, even though most drives' data was undamaged, and that every system crash required salvaging (traversing and checking) the entire directory hierarchy, an operation that grew with the size of the system's storage. Crashes on MIT's Multics system were common, and each crash required nearly an hour to recover. MIT also ran a CP/67 time-sharing system on the IBM 360/67, in the same room as the Honeywell 6180, and this machine could recover from a crash in a few minutes (because it didn't salvage user files at all -- that was up to individual users).
Customer sites like General Motors and Air Force Data Services wanted to increase the amount of disk storage on their Multics systems, but were limited by physical capacity and crash recovery time.
NSS Design
In 1973, we undertook a project to replace the lower levels of the Multics file system without changing the upper layer interface, to improve the system's capacity and reliability, and to provide new features such as support for removable packs. André Bensoussan and Steve Webber worked with me on defining the problem and choosing a direction. I changed jobs from MIT to CISL in 1974 -- I had already worked on Multics for seven years; André had been with Bull on loan to GE since the earliest days of CISL; and Steve had been a member of the original Multics file system implementation team, first at Project MAC and then at CISL.
We began with several hours of daily meetings, trying to decide the scope of our project. We wrote a Multics Technical Bulletin titled "The Storage Problem" that just described the issues we intended to address, without specifying how we planned to solve them. The "Multics Way" was to publish internal memos to the whole development team, and to ensure that all our colleagues had a chance to provide comments and suggestions. As our design continued, we wrote and distributed more MTBs, and discussed our plans and status with the rest of the team in group and individual meetings.
The important points of the new design were first, the division of file cataloging information between logical and physical, and the restriction that each segment's pages would reside entirely on one physical volume; second, new disk data organization on each volume for keeping track of segment contents; and third, the introduction of logical volumes, groups of physical volumes treated as a single allocation unit. Directories were constrained to a single logical volume, the Root Logical Volume (RLV), in order to avoid problems of verification of access control structures when volumes were dismounted and remounted. We called this project the New Storage System, to emphasize that the file system was unchanged, that only the way files were stored was changing.
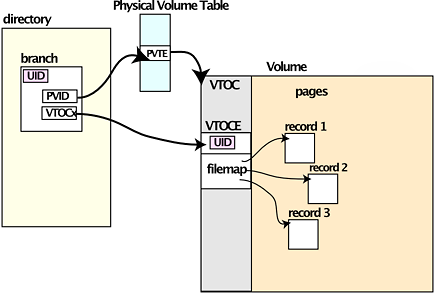
We were aware of the Unix file system design, where there was a similar split between naming data in directories and physical data in the inode; we split the data somewhat differently because we felt we had different requirements, including more stringent security needs. We called the data structure on each volume that cataloged an array of physical storage containers the Volume Table of Contents (VTOC). OS/360 had a similar structure for each of its volumes, and we chose to use the same name rather than make up a new one.
Special disk partitions had been defined for BOS support in the old file system; we changed the meaning of partitions, made them part of physical volumes, and introduced the notion of a hardcore partition used for the pages of the segments that constituted the supervisor, not actually part of the user-visible file system. Although this feature is very similar to some Unix systems' disk organization, this is a case of parallel invention.
Each directory was associated with a logical volume, and all segments in the directory took their storage from that logical volume. The volume attribute was inherited from the parent when a directory was created, unless a special option was invoked to create a "master" directory, similar to a Unix mount point. This enabled us to map disk quota management onto the naming and access control hierarchy, giving users a single set of controls for storage organization. Additional resource management and access control software was created to control the new demountable volumes. One reason we chose to keep directories on-line at all times was to support the Access Isolation Mechanism, which assigned security labels to each file. We also attached security classifications to each physical volume and matched these classifications with those of the master directories. Another reason to keep directories on-line was that it vastly simplified disk quota management.
We analyzed the causes of file system data loss, and took a thorough approach to damage prevention, damage limitation, damage detection, and automatic damage repair.
Special care was taken to manage disk addresses and free maps, so that any system interruption
would not leave a disk record part of two segments, or add records to the wrong segment.
The system's post-crash salvage operations were reorganized and made more robust.
Physical volumes were salvaged first, then directories.
Only physical volumes whose allocation tables were "dirty" needed salvaging.
In subsequent releases of NSS, the salvager was further improved,
so that the directory tree need not be walked after a crash:
instead, every item of directory data was ![]() checked before use,
and the directory salvaged during normal system operation and the operation restarted, if any problem was detected.
Physical volumes were also salvaged in parallel, using multiple processes, and thus, potentially, multiple CPUs, if necessary during system restart.
checked before use,
and the directory salvaged during normal system operation and the operation restarted, if any problem was detected.
Physical volumes were also salvaged in parallel, using multiple processes, and thus, potentially, multiple CPUs, if necessary during system restart.
The system operator interface was enhanced to support the new configuration and booting options, and to provide support for user mount requests and operator confirmation or denial. We simplified the operator interface and reduced the number of steps required to bring the system up, and supported unattended system restart, automatically invoking the salvagers when needed. If a disk volume crashed, the system could operate without it unless it contained directories. System dumping and reloading was also simplified and sped up. A subsystem to dump and restore the contents of physical volumes on a segment-by-segment basis, during system operation ("volume backup") was designed and implemented by Dave Vinograd.
Our goal was to provide equivalent performance, improved reliability and scalability, and new features without affecting any existing user programs.
We came very close to these goals. One area where we encountered a problem was the call to list a directory: the original design returned not only names but dates that we moved to the VTOC. This call slowed down a lot, since we had to do many VTOCE reads to obtain the dates. We introduced a new supervisor entry that returned only directory information and used it in all system software that didn't need the dates, and recommended that users call it whenever possible. We modified a few system commands to produce additional output, such as logical volume name; added a few new commands to deal with logical volume mounting; and also added a few new supervisor calls to support these additions, but almost all of the application program interface was unchanged.
When a new segment was created under NSS, the logical volume on which it was to reside was specified by the "logical volume" attribute of its parent directory, and the system chose a physical volume. Initially, we simply chose the physical volume (e.g. disk pack) with the most free storage, in order to balance I/O load and disk usage. Shortly after the system went into use at MIT, operations called and asked if they could add a new physical volume to a logical volume, without shutting down. This was a new feature of the system we were quite proud of, and we had tested it carefully, so we said OK. The volume added just fine, but then the MIT system slowed to a crawl, because all new segments were allocated on the new empty volume, and so that new volume was by far the busiest on the system. I think we had to force demount and evacuate the new volume and rush through a system change that used a better allocation algorithm.
If a physical volume filled up, and a user wished to grow a segment on the volume, some incredible code of Bernie's would invisibly move the segment to a different physical volume on the logical volume, without interrupting the user program. This segment mover was something we didn't realize we needed until part way through the design of the system. That we were able to fit it into the system was a confirmation that our basic approach was consistent and that we weren't doing violence to the design of Multics.
One neat feature we added to the system was page fault counts. Each segment had a counter added to its VTOCE that recorded the number of page faults ever taken on the segment; in other words, the number of page reads done on the segment since creation. We had administrative tools that could read the counters for all the segments in a logical volume and invoke the segment mover to move segments around to balance usage.
Building NSS
The first steps toward NSS were taken in late 1973, when we published the memo defining the problem. Steve, André, and I decided to have design meetings every morning until we came up with a design, and the basic design decisions were set within a few months. We continued design discussions, bringing in others at CISL and publishing more documents, and began coding in fall 1974.
Much of the hardcore supervisor had to be modified in order to support the new storage system. Bernie Greenberg, André Bensoussan, and I did most of the NSS programming. I served as project coordinator and program librarian. Noel Morris made major disk DIM improvements, Andy Kobziar and Susan Barr improved the salvager; at least 25 system programmers contributed to the NSS project. During this time, other Multics supervisor development and bug fixing continued. We had a parallel development stream for about a year, and used the Multics library tools and Bob Mullen's merge_ascii command (similar to Unix merge3) to keep the streams synchronized.
NSS reached command level in May 1975, but there was much more work to do until it was integrated into a production system. MCR 1582, "New version of storage system," was approved in December 1975, MSS 28.0 was installed for exposure at MIT in February 1976, and MR 4.0 provided NSS to general Multics customers in June 1976.
Improvements to the storage system continued for several years afterward. The salvager was completely rewritten and made much more robust, and many improvements were made in reliability, resource management, backup, and performance in releases 5.0 and 6.0.
We modified the data structures for directories and directory entries with redundant information to detect bad cataloging information, and instroduced the ability to invoke the salvager on the fly when a directory was found to be damaged, repairing the directory and retrying failing file system calls once. System reliability and availability were substantially improved.
References
The ![]() Multics Storage System Program Logic Manual, Honeywell Order No. AN61,
was written by Bernie Greenberg, and is a wonderful document, describing the internal workings of the Multics virtual memory and storage system.
I wrote a short note, "It Can Be Done," published in IEEE Computer, May 1994,
describing how André Bensoussan built the VTOC manager.
My notes for a talk at HLSUA in October 1974 reminded me of some details.
We have Multics Technical Bulletins scanned courtesy of the Multics History Project.
Multics Storage System Program Logic Manual, Honeywell Order No. AN61,
was written by Bernie Greenberg, and is a wonderful document, describing the internal workings of the Multics virtual memory and storage system.
I wrote a short note, "It Can Be Done," published in IEEE Computer, May 1994,
describing how André Bensoussan built the VTOC manager.
My notes for a talk at HLSUA in October 1974 reminded me of some details.
We have Multics Technical Bulletins scanned courtesy of the Multics History Project.
- MTB-017 The Storage Problem (1973-11-21)
- MTB-055 The New Storage System - Overview (1974-03-12)
- MTB-095 Adding Support for Secure Removable Disk Packs to Multics (1974-06-26)
- MTB-110 Implementation of Proposed New Storage System (1974-08-07)
- MTB-110 Implementation of Proposed New Storage System (1974-08-07)
- MTR-068 New Storage System Implementation Plans 10/74
- MTB-167 New Storage System Disk Usage (1975-02-28)
- MTR-081 New Storage System Long Range Plans 03/75
- MTB-206 SAVE and RESTOR for New Storage System (1975-06-18)
- MTR-095 New Storage System Long Range Plans 07/75
- MTB-229 Use of Demountable Logical Volumes (1975-10-08)
- MTB-238 Contents of Initial New Storage System at MIT (1975-11-18)
 MOSN-A001 Operational Changes for MR4.0 12/75
MOSN-A001 Operational Changes for MR4.0 12/75- MOSN-A002 Dumper and Reloader Changes for MR4.0 12/75
- Installation Instructions for MR4.0 12/75
- MTB-239 Storage System Error Recovery (1975-11-18)
- MTR-112 New Storage System Long Range Plans (Revised) 12/75
- MTB-243 Changes to User Ring Programs for New Storage System (1975-12-19)
- MTB-260 Interim Version of Mount and Demount for Disk Volumes (1976-02-24)
- MTR-120 Design Discussion of MTB-260 03/76
- MTR-119 New Storage System Long Range Plans 03/76